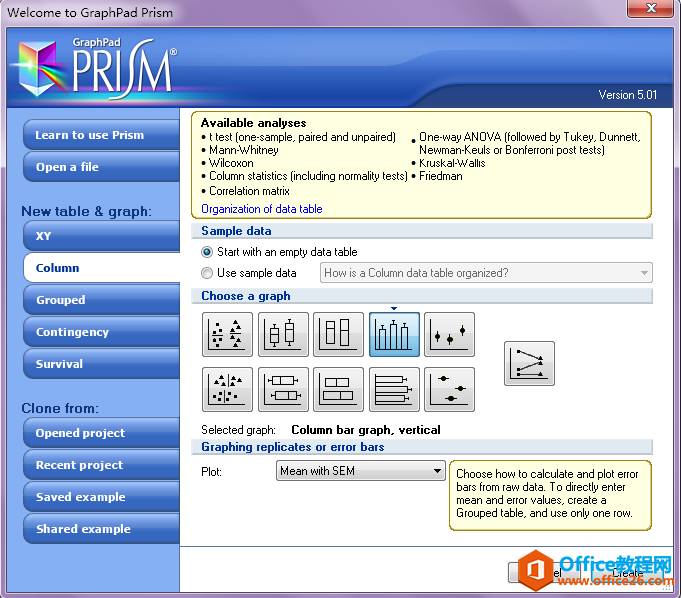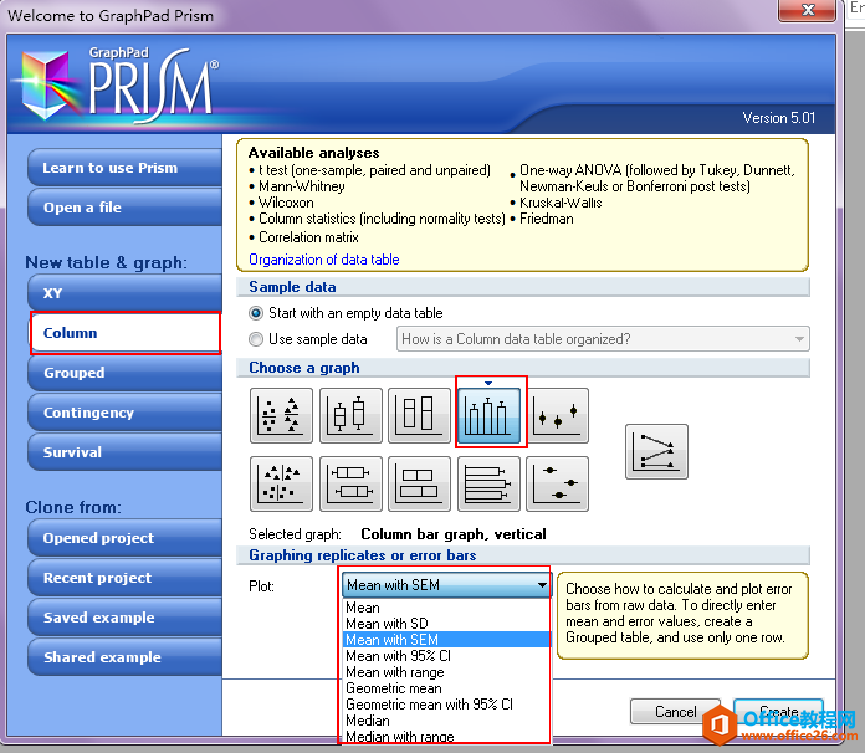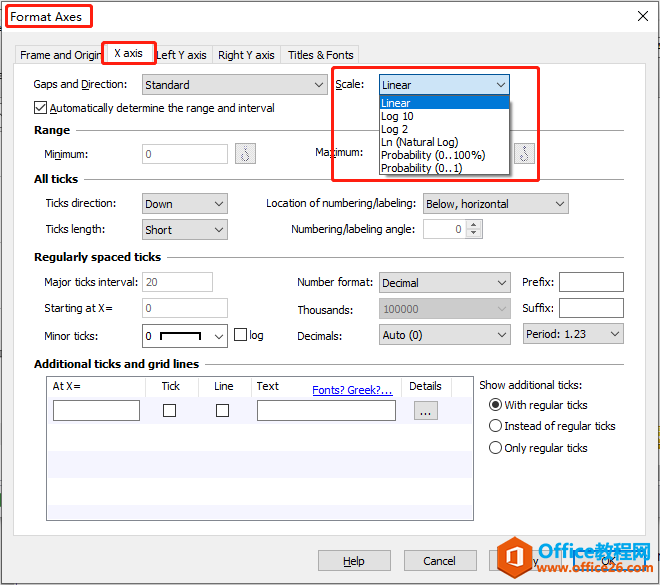
这篇文章,我们介绍一下如何让图表坐标轴以对数为刻度显示(只是显示方式的差别,这种操作不会改变你的数据),以及如何将原始数据转换为对数。创建一个对数刻度坐标轴在轴上双击打......
GraphPad Prism 统计分析时为什么会出现异常值(Outlier)?
EndNote
2022-04-28 21:44:04
什么是异常值?
在我们分析数据时,有时会发现一个值与其他值相差甚远。这类值称为 “异常值”,通常来说这个术语没有严格定义。在Prism的非线性回归中,异常值是远离稳健回归定义的最佳拟合曲线的点。
为什么会产生异常值?你需要先思考…
当你遇到异常值时,先不要急着把它从分析中删掉。可以先尝试问自己如下↓问题:
- 输入到计算机的值是否正确?如果是数据输入有误,先修正;
- 试验是否存在问题?比如,如果你注意到一根试管中的样本看起来很有趣,你可以用它作为排除该试管中样本所产生的值的理由,而无需执行任何计算;
- 是否由生物多样性引起的?如果每个值是来自不同的人或动物,那么异常值的存在可能是正确的。这类异常值,不是因为试验错误,而是因为那个人的操作可能与其他人不同。这或许是你数据中最令人兴奋的发现!
- 如果你对以上三个问题的回答均为“否”,那么还有两种可能:
- 异常值是由于偶然因素造成的。在此情况下,你应在分析中保留该值。该值与其他值来自相同的分布,因此应包括在内;
- 异常值是因为一个错误造成的。如错误的移液、电压尖峰、过滤器中的孔洞等。由于在分析中包含错误值会使结果无效,此时是需要删除的。也就是说,该值来自于不同于其他值的群体,并且具有误导性。
当然,问题是你永远不能确定这些可能性中哪一个是正确的。
何时需要剔除异常值?
像线性回归一样,非线性回归假设理想曲线周围的数据分散遵循高斯或正态分布。异常值可能违反了这一假设,并使非线性回归结果无效。为处理异常值,Prism提供了自动异常值剔除功能:
- 何时可以使用自动异常值剔除功能?
我们在做实验的时候难免会出现错误,这时可能会导致错误的值产生--异常值。即使是单个异常值也可能影响平方和计算,并导致误导性的结果。有些同学可能会认为随意剔除异常值是作假行为。其实那种通过特殊方式剔除“异常值” ,特别是只剔除妨碍获得想要结果的异常值时,才是作假行为。另外,留下以供分析的数据中的异常值也是一种作假,因为它可能会产生无效结果。
- 何时不建议使用自动异常值剔除功能?
- 拟合错误模型时,异常值消除会产生误导;
- 数据点不独立时,剔除异常值会产生误导;
- 所选加权因子不正确时,剔除异常值会产生误导。
异常值并非总是“坏”点
非线性回归通常可与实验数据一起使用,其中,X为变量(例如,时间或浓度)或在实验中调整的某些其他变量。由于所有分散都是由实验误差造成,而且我们几乎确定这由实验误差造成,所以,剔除所有极端异常值很有意义的。在其他情况下,每个数据点均可表示不同的个体。在此情况下,异常值可能不是由实验错误造成,而是由生物变异引起的,或者是模型中未包含的其他变量的差异。此时,异常值的存在可能成为研究中最有意义的发现。尽管在此情况下,ROUT异常值方法标记异常值可能很重要,但是在未深入思考(或进行实验)就自动排除这些异常值的情况下,就是大错特错了。在质量控制分析中,异常值可告诉你失控的过程。在未先了解该数值远离其他数值的原因时,不得删除异常值,异常值可能告诉你某些重要的信息。
Prism如何助你快速处理异常值?
在数据分析的过程中,我们需要首先识别异常值,然后判断异常值是否需要剔除。大家可看一下站内提供的全系列视频指南或者查看软件使用手册具体了解如何操作。
标签: GraphPadPrism统计分析时为什么会出现异常
相关文章
- 详细阅读
-
如何通过SPSS寻找最佳的曲线拟合方法详细阅读
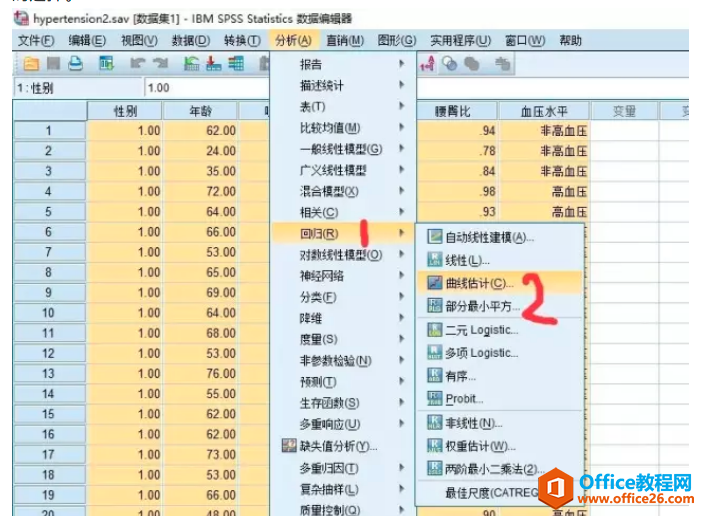
对于曲线拟合我们接触最多的就是一元线性回归。其实很多数据可能并不是直线关系,而是需要去探索其他的曲线拟合方式。今天我们来看看如何通过SPSS进行探索拟合方式的选择。这里有很多......
2022-04-28 412 SPSS SPSS曲线拟合方法
-
如何利用SPSS进行秩和检验详细阅读
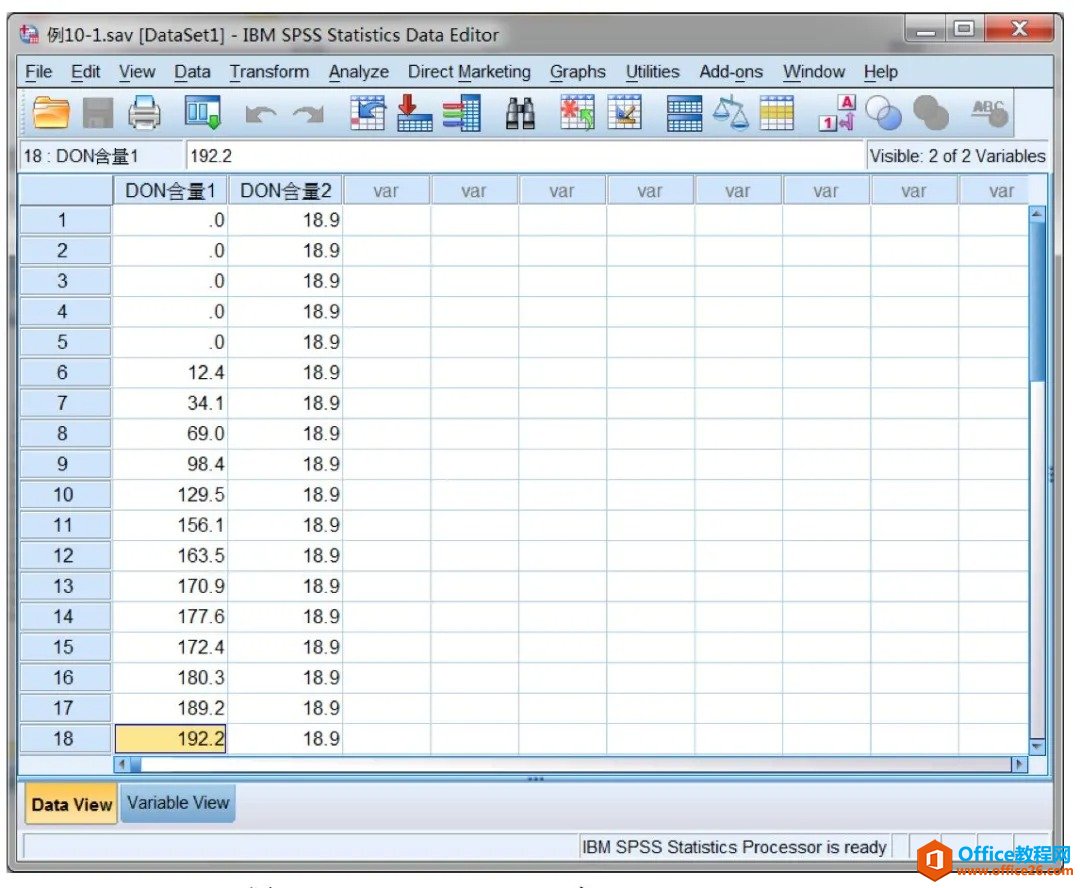
为研究大骨节病是否与粮食中DON含量有关,采集大骨节病高发地区面粉20份,测量面粉中DON含量,结果(g/g)如下:0,0,0,0,0,12.4,34.1,69.0,98.4,129.5,156.1,163.5,170.9,177.6,172.4,180.3,189.2,192.2,......
2022-04-28 400 SPSS SPSS进行秩和检验
- 详细阅读
- 详细阅读