access其最大的优点是:简单易学!非计算机专业的人员,也能学会。所以用它作为数据库的入门来学习是非常不错的选择。本文主要讲诉怎样一步步搭建一个小型的ACCESS数据库今天在确认实习......
如何使用Access进行海量数据分析?
Access
2021-09-18 09:09:36
业务上要处理的Excel数据表格存储量越来越大,超过30MB就慢如蜗牛,这时表格里要是再多个IF、VLOOKUP函数什么的,电脑就直接罢工了;要是遇到向下面这样大小的Excel表格,服务器级别的电脑都吃不消,更别谈进行数据处理和数据分析了。
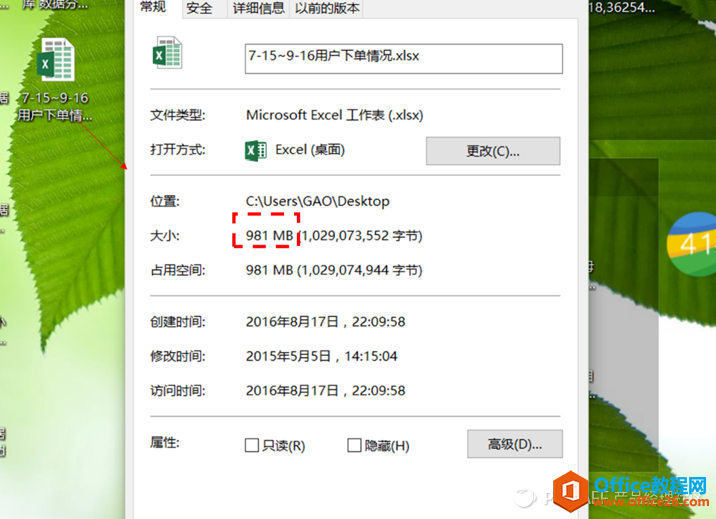
数据量超大的excel表格连打开都难
遇到上图这么大存储量的Excel数据表格,小喵和小伙伴们也是惊呆了,Excel玩转没多久,就遇到这样的难题,有没有能处理大存储量文件,同时又操作简单、容易上手的数据分析软件呢?
答案是当然是:YES,而且还是Excel的同宗兄弟,同属微软Office派系的ACCESS。
以下内容将以运营中常见的一个分析项目为案例(详情见“数据运营实操 | 如何运用数据分析对某个试运营项目进行“无死角”的复盘?”),力求让做数据分析的小伙伴们对ACCESS有一个基本的了解,从而找到分析大批量数据的思路和方法。
下图是本文使用ACCESS对原始表格进行数据分析的4大目标。

本文使用ACCESS进行数据分析的4大目标
小喵先就ACCESS的基本情况说两句,然后用一个实际案例进行数据分析的实操。
一、ACCESS数据库简介
1.ACCESS和SQL语句的基本概念
Access,全称“Microsoft Office Access”,是微软OFFICE中的一个成员, 由微软发布的关系数据库管理系统。它结合了 Microsoft Jet Database Engine 和图形用户界面两项特点,是 Microsoft Office 的系统程序之一。(来自百度百科)
提到ACCESS,就不得不提SQL,只有掌握了SQL,才能将ACCESS的功能发挥到极致。SQL的全称是“结构化查询语言”(Structured Query Language),是一种声明式语言。
首先要把这个概念记在脑中:“声明”。跟大家以往所知的编程语言相比, SQL 语言是为计算机声明了一个你想从原始数据中获得什么样的结果的一个范例,而不是告诉计算机如何能够得到结果。换言之,SQL的真正核心在于对表的引用。
SELECT first_name, last_name FROM employees WHERE age> =25
上面的例子很容易理解,我们不用关心这些雇员记录从哪里来,我们所需要的只是那些年龄大于等于25岁的雇员的数据(age> =25)。
2.ACCESS的优势
ACCESS最明显的好处在于,它可以在不用掌握很高深编程语言的条件下,处理Excel所不能承载的大存储量的数据原始文件,速度奇快,且易学易用。
 使用ACCESS的优势
使用ACCESS的优势
3. ACCESS的常用语句
下表是ACCESS使用过程中常用的一些SQL语句,理解起来不算困难。
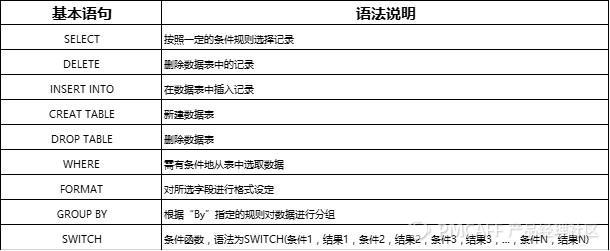
ACCESS数据库常用的SQL语句
要想学好数据分析工具,最重要的是用实际案例来调动各种零碎的工具使用知识点,在历经完整的案例分析后,短时间内就可以掌握这些工具的操作方法。
简单介绍完了ACCESS和SQL语句后,让小喵带着大家开始ACCESS数据分析实操吧!
二、ACCESS数据分析实操
1.数据导入
下表是本文进行ACCESS数据分析的原始文件,数据量近230MB,Excel打开需等待好几分钟,而且得看电脑心情…出于商业保密的目的,本文将使用其中的部分数据进行分析实操,且做一定处理。
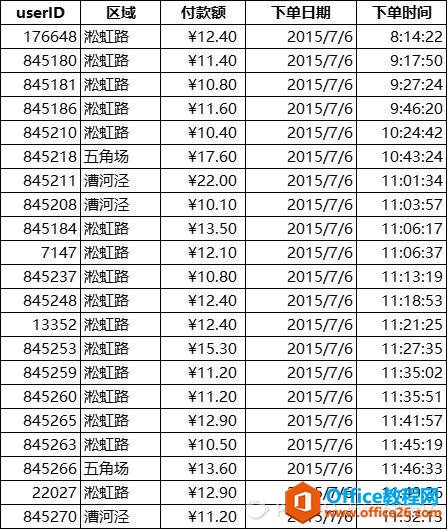
后台导出的原始数据
先将Excel中的文件导入ACCESS中,按下图箭头路径所示:
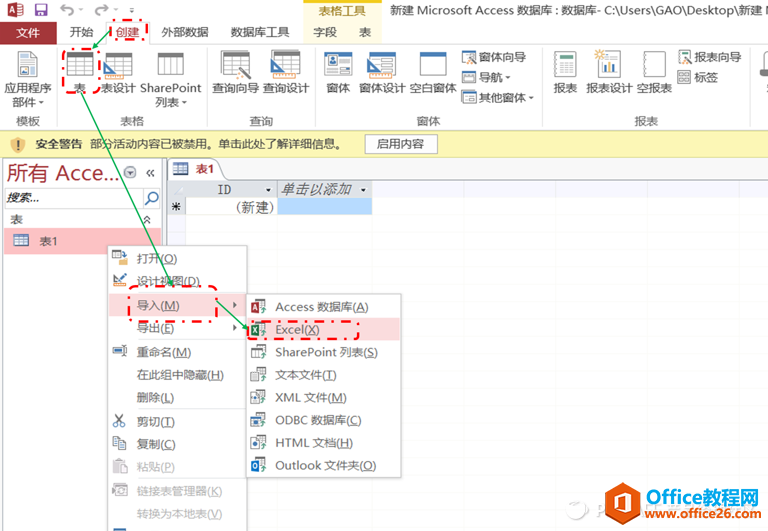
导入excel原始数据文件
按上述步骤操作后,自动生成主键(即ID),得到如下结果:
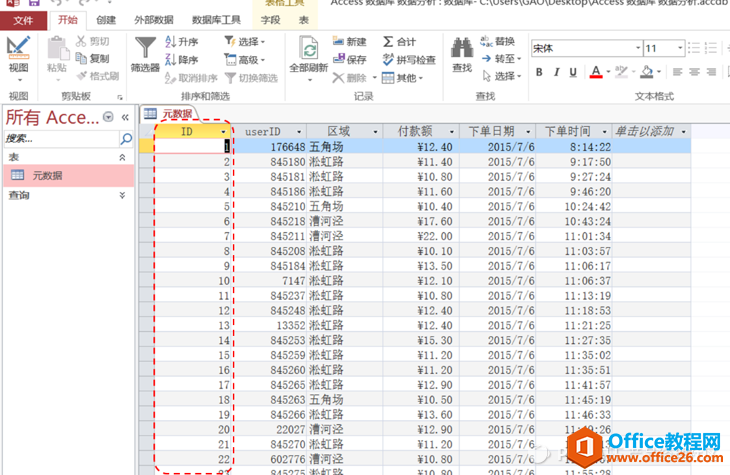
Excel原始数据文件导入到ACCESS中
2.用户下单时间段分析
进行下单时间段的分析,需要将用户下单的时间转化为小时“时点”,这里使用的SQL语句是format,功能是对所选字段进行格式设定,语法为:
format(引用字段,"数据格式")
其中,“数据格式”在时间上一般选用H(小时)、D(天)、M(月)或Y(年)。
然后,再使用count函数,将UserID进行计数,得到的结果即是订单量。
注意,使用format和count之后,需要使用“AS”将其定义为新的字段,这里二者分别定义为“时段”和“订单量”。
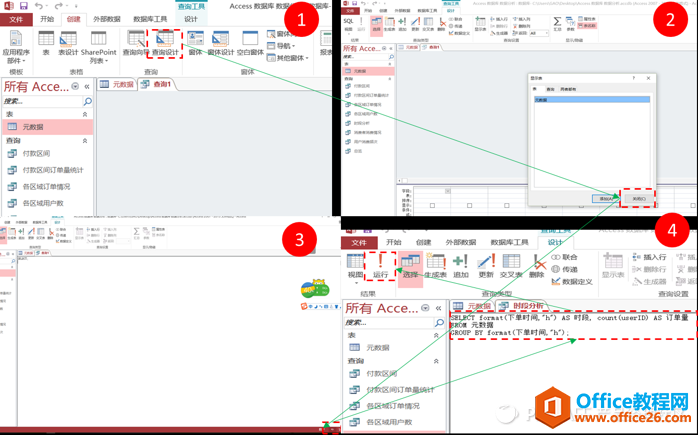
下单时间段分析操作步骤
在“创建”里新建一个“查询设计”,点开右下角的“SQL”,然后在SQL会话框输入如下语句:
SELECT format(下单时间,"h") AS 时段, count(UserID) AS 订单量
FROM 元数据
GROUP BY format(下单时间,"h");
然后,点击“设计”下的“运行”,得到如下结果:
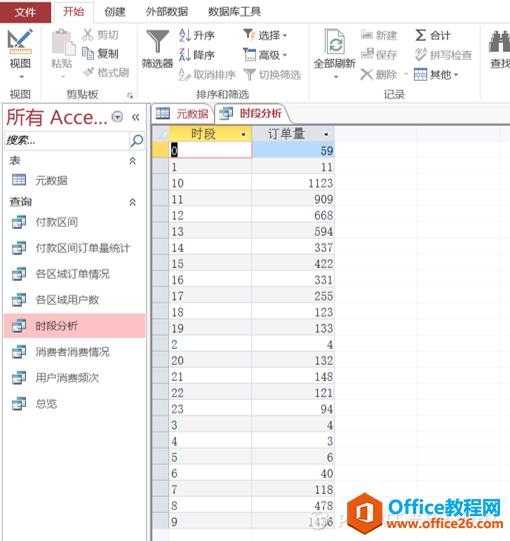
各个时段的订单量分布情况
举个例子来说明上面的结果该如何解读,假如某位顾客是12:23下单,则该时间点归到“12”这个时段里了,而“12”代表的是12~13时这个时间段。可以根据“运营实操|如何利用微信后台数据优化微信运营”这篇文章里的方法利用函数将其变为时段显示。
3.付款区间订单量分布情况分析
计算付款区间需要用到一个比较牛X的函数--- Switch,它是按顺序计算一系列的表达式,如果某一表达式成立,则返回其随后的值。
语法:
SWITCH(条件1,结果1,条件2,结果2,条件3,结果3,…,条件N,结果N)
条件1、条件2、条件3:表示要计算的表达式,条件1成立的话,返回值结果1,条件2成立的话,返回值结果2,依次类推。
按照上述的方法,在“创建”里新建一个“查询设计”,点开右下角的“SQL”后,输入如下语句:
SELECT userID, 付款额, switch(付款额<=10,"1~10元",
付款额<=20,"11~20元",
付款额<=50,"21~50元",
付款额<=80,"51~80元",
付款额<=150,"81~150元",
付款额>150,"151~220元")AS 消费区间
FROM 元数据;
点击“运行”后,得到如下结果:
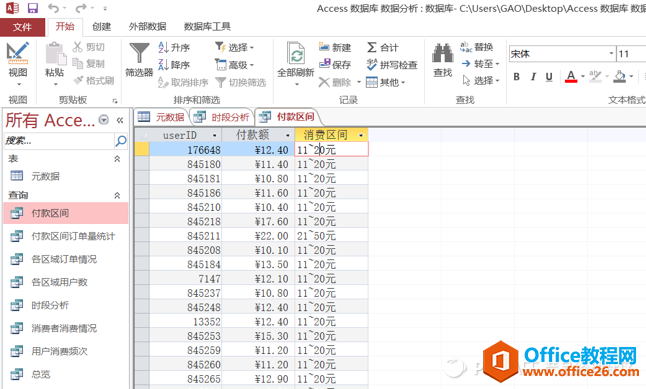
用户单次下单的消费金额所对应的消费区间
此时,关于消费区间的数据处理还未结束,因为这是每一条下单记录的付款额所对应的消费区间。我们接下来要做的是类似于excel中数据透视表的做法,将消费区间放在第一列,从而对每个消费区间有多少订单量进行统计。
所以呢,跟上面一样,得新建一个查询了,名称改为“付款区间订单量统计”。
这里需要输入的SQL语句是:
SELECT 消费区间, count(UserID) AS 订单数量
FROM 付款区间
GROUP BY 消费区间;
点击“运行”后,得到的结果显示如下:
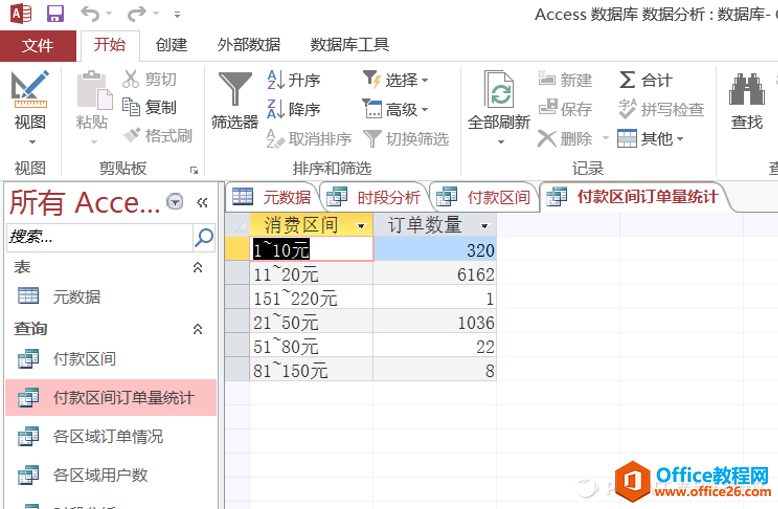
各消费区间订单量分布情况
然后,将上述数据复制到Excel表格里,制成如下的百分比扇形图,可以直观的分析出每个消费区间的订单量占比情况,进而看到整体的用户消费水平如何,对这段时间内的运营进行合理评估。
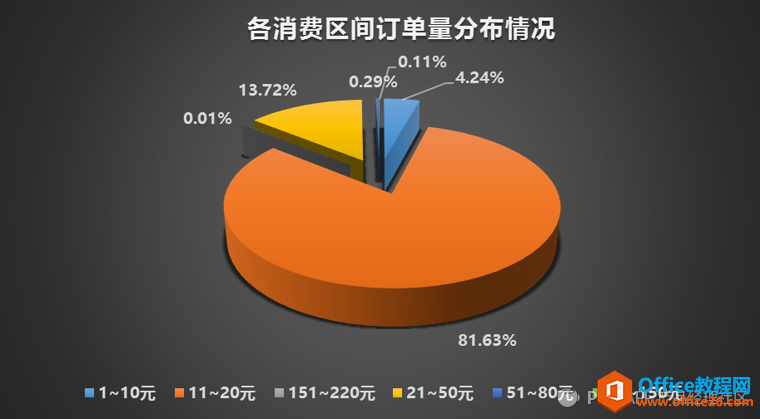
各消费区间订单量占比扇形图
4.各区域订单量、用户数量及销售额分析
(1)各区域用户数量
这个就有点小麻烦了,用户数量用“userID”的计数间接计算出来,但是由于绝大部分的用户下单次数不小于2次,所以直接计数的话,得出来的结果就是订单量了。鉴于此种情况,我们得换个思路,先做出一个不重复的用户下单信息表,也就是每个用户ID下单的频次表。
新建一个“查询设计”,命名为“用户消费频次”。在SQL对话框里输入如下语句:
SELECT UserID, COUNT(UserID) AS 消费次数, 区域
FROM 元数据
GROUP BY UserID, 区域;
点击“运行”后,得到的结果显示如下:
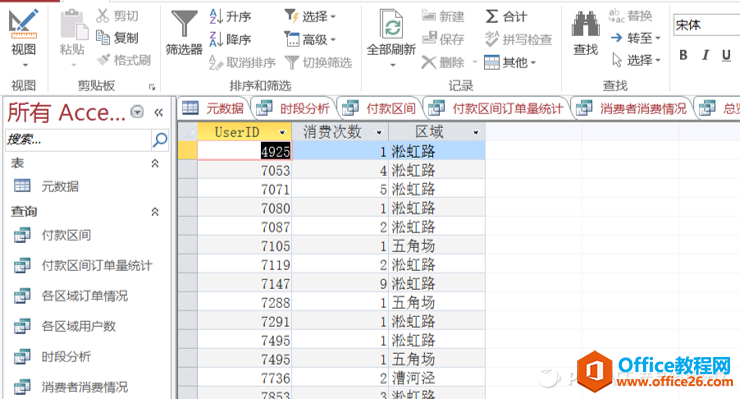
用户下单频次表
这样,我们就可以以这张用户消费频次表作为跳板,在再次新建的表里计算出每个区域的用户数量咯。
新建一个“查询设计”,命名为“各区域用户数”。在SQL对话框里输入如下语句:
SELECT 区域, count(UserID) AS 总用户数
FROM 用户消费频次
GROUP BY 区域;
点击“运行”后,得到的结果显示如下:
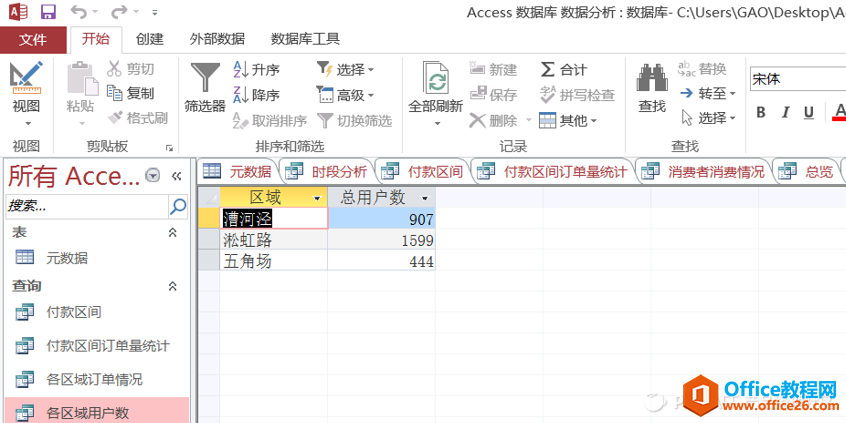
各区域用户数量
(2)各区域订单量、消费金额状况
新建一个“查询设计”,命名为“各区域订单情况”。在SQL对话框里输入如下语句:
SELECT 区域, count(UserID) AS 订单总数, sum(付款额) AS 总金额, avg(付款额)AS 平均消费金额
FROM 元数据
GROUP BY 区域;
点击“运行”后,得到的结果显示如下:
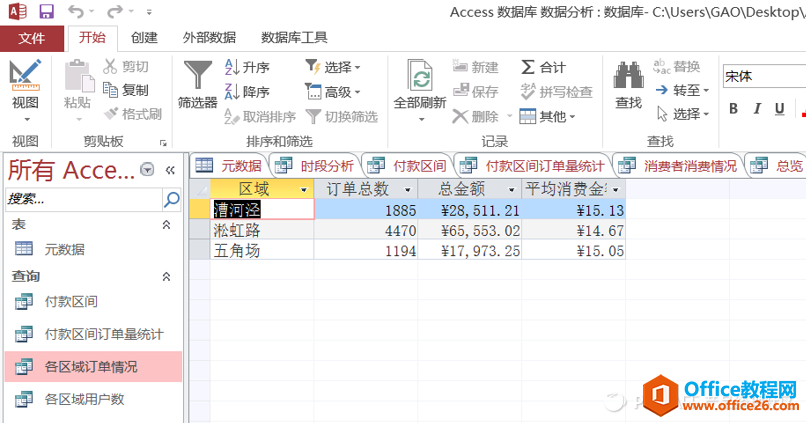
各区域订单量、消费金额状况
再将上面的各区域用户数量整合到这张表里,就得到了关于这三个区域完整的运营情况概览表。见下表:
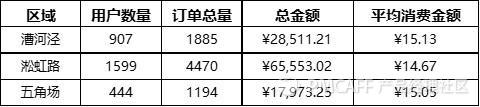
各区域运营情况概览
6.用户价值分析
这里的用户价值分析基于RFM模型,不过对其进行了进一步的完善,在原先“累计消费金额”的基础上,引入了“最低消费金额”、“最高消费金额”和“平均消费金额”这三个指标,力求全面的反映消费者的购买力。
新建一个“查询设计”,命名为“用户消费情况”。在SQL对话框里输入如下语句:
SELECT userID, min(付款额) AS 最低消费金额,
max(付款额) AS 最高消费金额,
avg(付款额) AS 平均消费金额,
sum(付款额) AS 消费总金额,
count(付款额) AS 消费频次,
datediff("d",max(下单日期),#2015-9-15#) AS 最近一次消费距离今天天数
FROM 元数据
GROUP BY userID;
点击“运行”后,得到的结果显示如下:
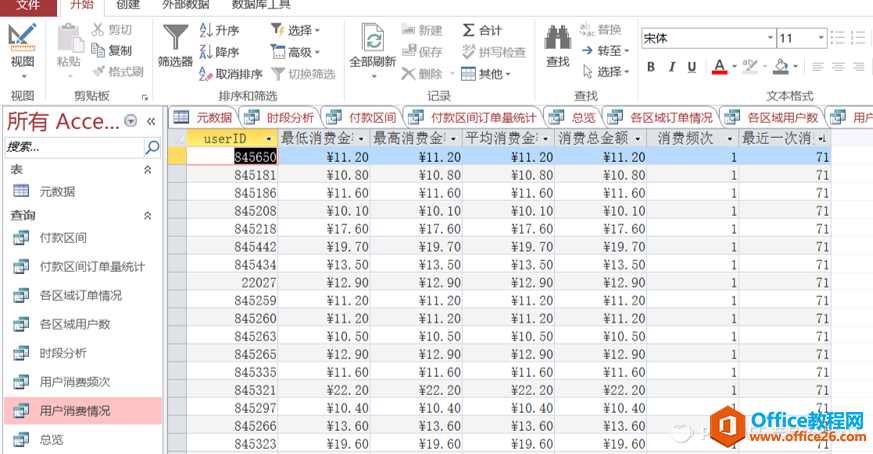
用户价值分析表
得到该表后,可以对其进行聚类分析,按照R、F、M这三个维度对用户进行分类,详情可参看“【数据运营实操】如何运用数据分析对某个试运营项目进行“无死角”的复盘?”这篇文章。
最后,我们还可以得出这三个区域总的订单情况和销售金额情况:
新建一个“查询设计”,命名为“各区域销售总览”。在SQL对话框里输入如下语句:
SELECT count(userID) AS 订单总数,
sum(付款额) AS 付款总额,
avg(付款额) AS 平均订单金额
FROM 元数据;
点击“运行”后,得到的结果显示如下:
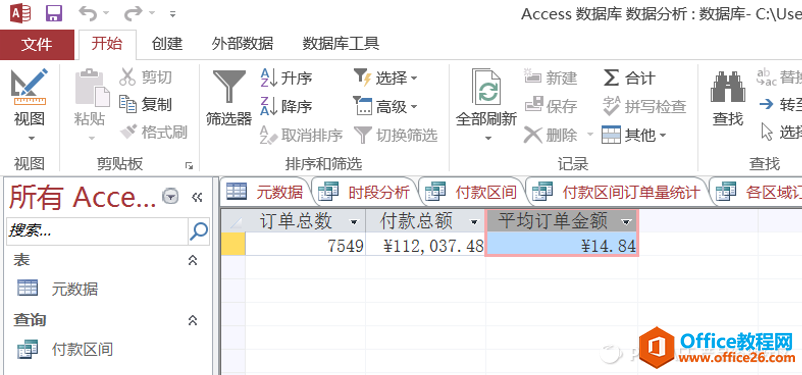
三个区域的销售情况总览
结语
由上面的案例可以看出,如果SQL语句用得稍微熟练的话,ACCESS处理数据不会比Excel逊色,而且处理大批量数据正是它的强项。
标签: Access海量数据分析
相关文章
- 详细阅读
- 详细阅读
- 详细阅读
-
Access2016数据库开发教程1详细阅读

第一章开发平台概述1.1盟威软件快速开发平台是什么?1.1.1概述《盟威软件快速开发平台(Access版)》是一款免费的快速开发平台。该平台主要用于企业中各种管理信息系统的开发,不会编程的......
2022-04-19 488 Access Access2016 Access2016数据库开发 数据库开发
- 详细阅读